Was Teams meist beantworten können
- Welche Bugs offen sind
- Welche Incidents passiert sind
- Welche Themen gerade wehtun
Produktpilot für eine evidenzbasierte Bug-Analyse
Ticket Triage verbindet GitLab-Tickets mit Code-Änderungen und zeigt, welche Muster immer wieder auftauchen, was dahintersteckt und wo sich ein Eingriff am ehesten lohnt.
Für Teams, die wiederkehrende Bugs nicht länger nur diskutieren, sondern fundiertert und systematisch handeln wollen.
Das Problem
Die entscheidenden Hinweise stecken verteilt in Tickets, Fixes und im Wissen einzelner Leute. Genau deshalb ist Priorisierung oft schwer sauber zu begründen.
Wenn die gemeinsame Faktenbasis fehlt, gewinnt fast immer das Tagesgeschäft.
Was der Pilot liefert
Kein weiteres Dashboard. Eine gezielte Analyse, die eure Bug-Historie für Entscheidungen nutzbar macht.
Wir bringen Bug-Tickets, verknüpfte Merge Requests und Diffs zusammen, damit die Analyse auf eurer tatsächlichen Entwicklungsarbeit basiert.
Ihr seht, welche Muster immer wieder auftauchen, welche Themen sich durch viele Tickets ziehen und wo sich Hotspots bilden.
Der Pilot zeigt belastbare Ansatzpunkte auf, ohne euch eine konkrete Maßnahme vorzugeben.
Ablauf
Ein System, ein Zeitfenster, ein definierter Scope und am Ende ein Ergebnis, das ihr gemeinsam prüfen könnt.
In drei Schritten von eurer Bug-Historie zu einer besseren Priorisierungsgrundlage.
Gemeinsam wählen wir ein Team oder System aus, legen das Zeitfenster fest und prüfen, ob Tickets und Code-Änderungen sauber genug verknüpft sind.
Die Analyse zeigt, welche Muster wiederkehren, was die Probleme wahrscheinlich treibt und wo sie sich im Code bündeln.
Ihr könnt die Ergebnisse im Produkt nachvollziehen, Rückfragen stellen und die Erkenntnisse einordnen.
Was ihr bekommt
Die Resultate sind so aufbereitet, dass ihr sie gemeinsam prüfen, einordnen und für die nächsten Entscheidungen nutzen könnt.
Ihr seht, welche Muster besonders häufig auftauchen und wo sich Aufwand und Wirkung bündeln.
Ihr erkennt Themen, die sich über viele Tickets hinweg wiederholen und immer wieder Probleme auslösen.
Ihr seht, welche Bereiche im Code besonders oft von Bug-Fixes betroffen sind und wo sich ein genauerer Blick lohnt.
Dazu gehören die nachvollziehbaren Ergebnisse im Produkt und ein zusammenfassender Bericht.
Belege
Die Analyse bleibt überprüfbar, weil ihr von den Mustern bis zu den zugrunde liegenden Tickets und Änderungen zurückgehen könnt.
Wiederkehrende Muster
So wird klarer, was den Bug-Fix-Aufwand tatsächlich treibt, sodass Priorisierung nicht mehr auf Bauchgefühl beruhen.
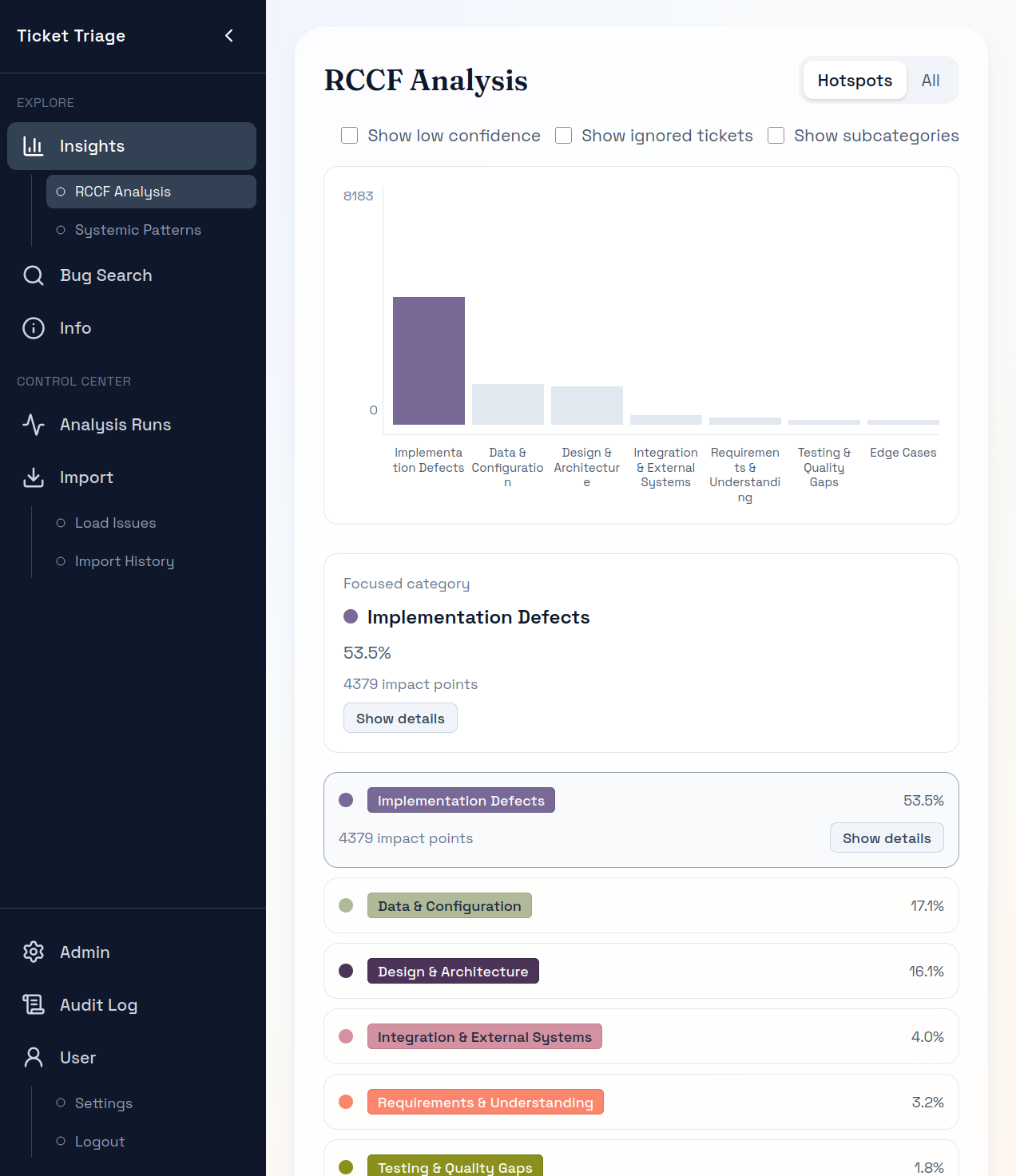
Nachvollziehbar
Begründungen, Unterkategorien und verknüpfte Tickets bleiben sichtbar und überprüfbar.
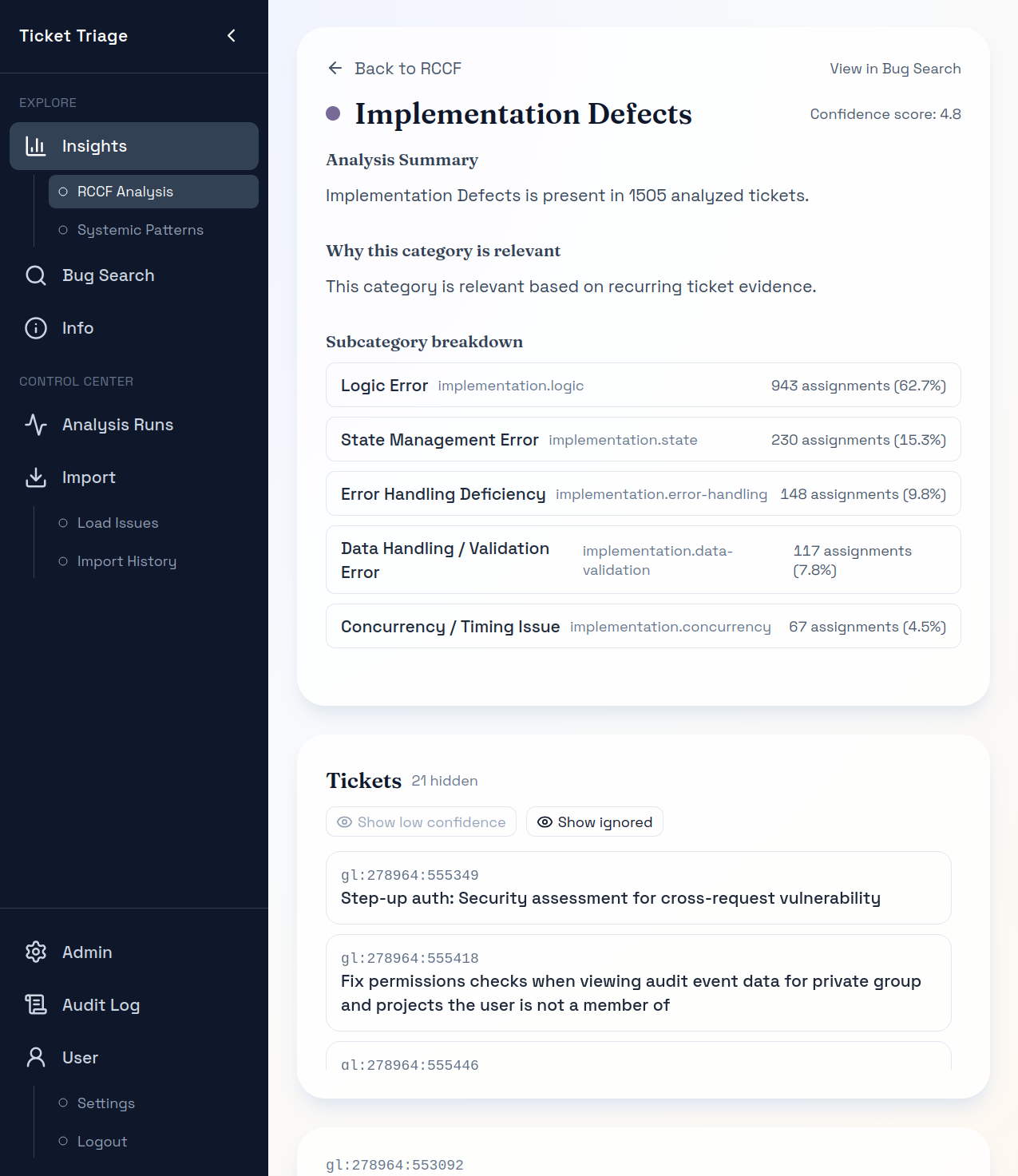
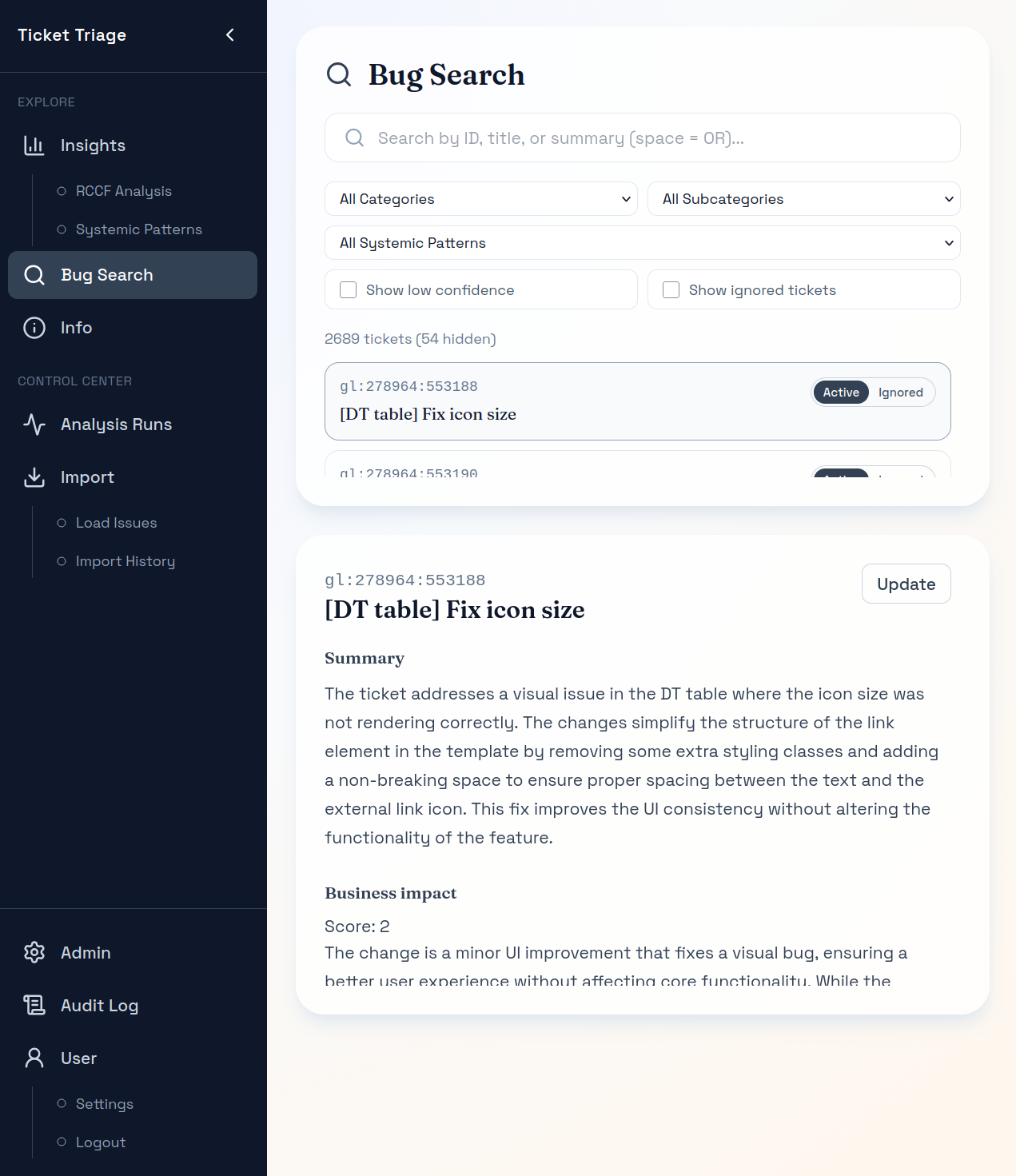
Ticketnah
Einzelne Tickets lassen sich direkt öffnen, um Kontext und Aussagekraft der Analyse zu prüfen.
Warum Teams darauf setzen
Pilot
Der Scope bleibt bewusst überschaubar, damit ihr mit wenig Risiko prüfen könnt, ob der Ansatz für euch Mehrwert bringt.
Am besten geeignet für
Im Pilot enthalten
Pilot-Scope: Ein System oder Team, GitLab-Issues, ein Code-Host, ein Analyse-Lauf, strukturierter Review-Termin und 2 Wochen Produkt Zugriff.
Betrieb: Läuft in eurer Umgebung mit eurem eigenen OpenAI-Zugang (BYOK).
Zusätzliche Konnektoren: Alternativen zu OpenAI oder GitLab stimmen wir separat ab.
Preis: Nach Absprache
FAQ
Diese Tools helfen dabei, laufende Systeme zu überwachen, codebezogene Probleme sichtbar zu machen oder technische Signale auszuwerten. Ticket Triage beantwortet eine andere Frage: Was kehrt in euren historischen GitLab-Bug- und Fix-Daten immer wieder zurück, was sind die wahrscheinlichen Treiber dahinter, und wo sollte man zuerst ansetzen? Es geht um belastbare Priorisierung bei wiederkehrenden Defekten, nicht um ein weiteres Dashboard.
Für den aktuellen Standard-Piloten ist GitLab als Ticket- und Code-Quelle erforderlich. Die Analyse basiert auf GitLab Issues und verknüpften Code-Änderungen; OpenAI wird über BYOK eingebunden. Weitere Konnektoren gehören derzeit nicht zum Standardscope und müssten separat vereinbart werden.
Ihr erhaltet ein belastbares, datenbasiertes Bild der dominanten wiederkehrenden Fehlermuster im gewählten Scope, der ticketübergreifenden Muster mit dem größten Engineering-Aufwand, der Codebereiche mit besonderer Defektkonzentration sowie die Rückverfolgbarkeit bis auf die zugrunde liegenden Tickets und Code-Änderungen. Das praktische Ergebnis ist eine deutlich fundiertere Entscheidung darüber, wo Qualitäts- und Zuverlässigkeitsarbeit als Nächstes ansetzen sollte.
Es ist ein produktgeführter Pilot. Die Software übernimmt die Analyse und gibt eurem Team read-only Zugriff, um die Ergebnisse direkt im Produkt nachzuvollziehen. Der Pilot ergänzt das um einen klar abgegrenzten Scope und strukturierte Termine, damit ein ausgewähltes Team oder System zu einer belastbaren Entscheidung kommt - ohne daraus gleich einen größeren Rollout oder ein Consulting-Projekt zu machen.
Das Setup ist bewusst schlank gehalten: ein ausgewähltes Team oder System, ein historischer GitLab-Datensatz, klar definierte Zugriffe und ein abgegrenzter Analyse-Run. Wir starten mit einer kurzen Datenqualifizierung und liefern die Ergebnisse anschließend im Produkt aus, statt ein laufendes Monitoring aufzusetzen.
Weil die Ergebnisse überprüfbar sind. Ihr könnt sie im Produkt bis auf die zugrunde liegenden Tickets, verknüpften Merge Requests und Code-Änderungen zurückverfolgen. Das Ziel ist nicht, die Einschätzung des Teams zu ersetzen, sondern Qualitätsdiskussionen weniger anekdotisch und deutlich belastbarer zu machen.
Der Pilot ist bewusst mit geringem Footprint angelegt: single-tenant, customer-hosted oder kundenseitig kontrolliertes Deployment mit BYOK, klar begrenzter Scope und eindeutig eingegrenzter Datenzugriff für das ausgewählte Team oder System. Dadurch ist der Pilot in der Regel deutlich einfacher zu prüfen als ein breiterer Rollout.
Nein. Der Pilot zeigt auf, wo sich wiederkehrende Fehlermuster konzentrieren, und macht die vorrangigen Handlungsfelder mit möglichen Stoßrichtungen sichtbar. Was priorisiert wird, wie gehandelt wird und ob überhaupt gehandelt wird, entscheidet weiterhin euer Team.
Weil der Pilot vorhandene GitLab-Historie nutzt, um ohne größeren Rollout eine belastbare Priorisierungsentscheidung zu ermöglichen. Er hilft Teams dabei, wiederkehrenden Bug-Druck in einen klar begründbaren nächsten Schritt zu übersetzen.
Am besten geeignet ist ein klar abgegrenztes, GitLab-basiertes Team oder System mit etwa 6-12 Monaten relevanter Bug-Historie und zumindest einer sinnvollen Verknüpfung zu Merge Requests oder Commits. Je klarer Ownership und Historie sind, desto belastbarer werden die Erkenntnisse.
Nächster Schritt
Wir gehen eure Bug-Historie gemeinsam durch und schauen, ob sich daraus ein klarer Pilot mit echtem Nutzen zuschneiden lässt.